¶ 데이터베이스 선택 가이드
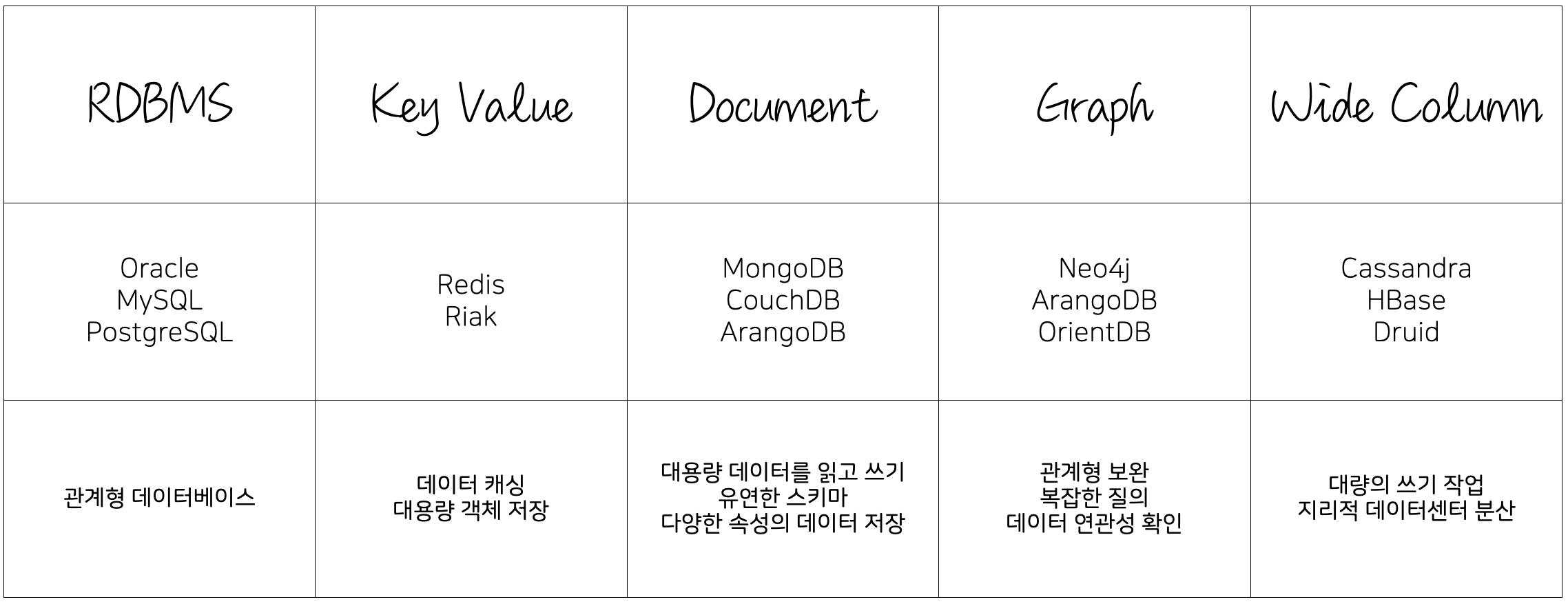
¶ 데이터베이스 종류
¶ 1. 관계형 데이터베이스(RDBMS)
- 관계형 데이터베이스는 테이블(행·열) 구조를 기반으로 데이터를 저장한다.
- ACID(Atomicity, Consistency, Isolation, Durability) 특성을 통해 트랜잭션 무결성을 보장한다.
- 스키마가 엄격히 정의되어 있어 데이터 무결성 유지가 용이하다.
- JOIN 연산으로 복잡한 관계 탐색이 가능하다.
- 대표적 RDBMS 예시로 MySQL, PostgreSQL, Oracle, SQL Server가 있다. 이들 제품은 표준 SQL을 사용하여 데이터 정의ㆍ조작ㆍ제어를 수행한다.
¶ 2. 비관계형 데이터베이스(NoSQL)
- NoSQL(“Not Only SQL”)은 전통적 테이블 기반 구조 대신 단일 데이터 모델을 사용하여 데이터를 저장ㆍ조회한다.
- 고정된 스키마가 필요 없으며, 수평 확장(horizontal scaling)에 최적화되어 대용량ㆍ실시간 처리에 적합하다.
¶ 2.1 Key-Value 스토어
- 모델은 키와 값의 쌍으로 데이터를 저장하는 단순 구조이다.
- 조회 성능이 뛰어나 캐시나 세션 스토어에 자주 활용된다.
- 대표 제품으로 Redis, Amazon DynamoDB, Riak, Memcached가 있다.
¶ 2.2 Document 스토어
- 모델은 JSON, BSON, XML 등의 문서 단위로 데이터를 저장하며 문서 내부에 다양한 구조를 허용한다.
- 유연한 필드 스키마와 복합 쿼리 지원, 자동 인덱싱 기능을 통해 문서 지향 작업에 최적화된다.
- 대표 제품으로 MongoDB, Couchbase, RavenDB, Elasticsearch가 있다.
¶ 2.3 Wide-Column 스토어
- 모델은 컬럼 패밀리(Column Family) 구조를 사용하며 Bigtable 스타일을 따른다.
- 행(row)별로 가변적인 컬럼을 가질 수 있어 대규모 분산 처리와 수평 확장에 강하다.
- 대표 제품으로 Apache Cassandra, HBase, Google Bigtable, ScyllaDB가 있다.
¶ 2.4 Graph 데이터베이스
- 모델은 노드(Node)와 엣지(Edge)로 구성된 그래프 구조를 사용한다.
- 복잡한 관계 탐색(최단 경로, 패턴 매칭)에 최적화되어 소셜 네트워크나 추천 시스템에 적합하다.
- 대표 제품으로 Neo4j, Amazon Neptune, ArangoDB, OrientDB가 있다.
¶ 2.5 In-Memory 데이터베이스
- 모델은 RAM(Main Memory)에 데이터를 상주시켜 디스크 I/O 없이 초고속으로 액세스한다.
- 마이크로초 단위 응답 시간을 제공하며 실시간 분석ㆍ트랜잭션 처리에 최적화된다.
- 다만 내구성을 위한 복제ㆍ백업 전략이 필수적이다.
- 대표 제품으로 Redis, SAP HANA, Apache Ignite, Memcached가 있다.
위 분류를 바탕으로 각 데이터베이스의 데이터 모델, 확장성, 일관성 요구사항, 성능 특성을 비교ㆍ검토하여 시스템 요구사항에 맞는 최적의 기종을 선택한다.
¶ 데이터베이스 선택시 고려사항
| 질문 | RDBMS | NoSQL |
|---|---|---|
| 트랜잭션에 대한 보장이 필요한가? | MySQL, PostgreSQL | MongoDB |
| 복잡한 Join 연산이 필요한가? | PostgreSQL | Neo4J |
| 쓰기가 읽기보다 많다 | — | Cassandra, Redis |
| 속도가 중요하다 | — | Redis, MongoDB, CouchbaseDB |
| 지리정보(GIS)를 저장해야 한다 | PostgreSQL | MongoDB |
| 기기나 솔루션에서 자체적인 정보를 저장이 필요하다 | SQLite | Realm |
| 대규모 분산처리가 필요하다 | — | MongoDB, Cassandra |
| 단순한 key:value 타입의 저장이 필요하다 | — | Redis, DynamoDB |
¶ Data Warehouse
- 통계 및 전처리 된 데이터를 저장하기 위한 DW는 별개의 영역으로 둔다.
- OLAP 시스템의 스키마는 일반적인 서비스 OLTP의 스키마와 설계 방식이 다르다.
- 오픈소스 DW 저장소로는 Click House, Apache Druid 등이 있다.
¶ Log 저장소
¶ Log를 데이터베이스에서 분리해야하는 이유
- 로그는 데이터가 빠르게 많이 쌓이기 때문에 DB에 저장시 서비스에 영향을 줄 수 있다.
- 서비스 레벨에서 자주 조회되어야 하는 Log 데이터를 어디에 적재할 것인지 결정하는 건 어려운일이다.
- 로그 적재 시스템이 분리되어 있다면 서비스 장애시에도 로그가 계속 쌓여 원인을 찾기 쉽다.
¶ Log를 분리해서 저장하는 방법
- AWS를 이용하는 경우 S3를 이용하는 것은 좋은 방법중에 하나이다. 아이스버그가 지원되기 때문에 S3에 별도의 메타데이터를 저장할 수 있다.
- 로그의 내용이 코드가 아닌 자연어 스타일로 되어 있다면, MongoDB나 Elastic Search 같은 Fulltext 검색이 용이한 저장소를 선택하는 것도 방법이다.